「3B参数指挥智能体」如何让Token成本直降68%:一个工程师的深度复盘
多智能体协作的困境,本质上是协作结构的失效。2025年主流方案中,ClaudeCode的AgentTeams采用并行调用策略,在提升能力上限的同时带来了极高的Token消耗;OpenClaw通过技能组合实现多智能体管理,在工程可控性上有所突破。但这两类方案都存在一个根本性缺陷:协作结构依赖预定义规则,无法根据任务难度动态调整。
协作结构的根本缺陷
这种设计导致一个严重后果:修自行车与造火箭都派同一个十人专家组开三天会。简单任务消耗了大量不必要的Token,复杂任务又受限于固定拓扑的表达能力。开发者面临两难选择,要么成本失控,要么能力受限。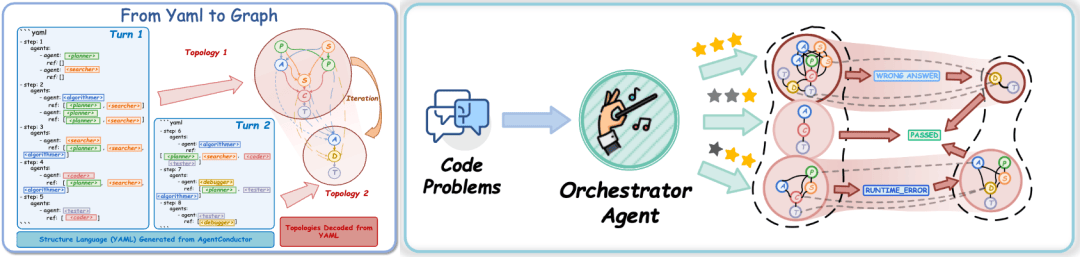
任务难度的动态评估机制
上海交通大学i-WiN团队提出的AgentConductor框架,通过引入一个3B参数的指挥智能体,从根本上解决了这一问题。该框架的核心创新在于:指挥智能体首先评估任务难度,然后动态生成适配的YAML交互拓扑图。
具体而言,简单任务触发轻量团队配置,复杂任务激活更复杂的交互图。这种自适应的能力与成本匹配机制,使系统在保持高效的同时显著降低了资源消耗。
拓扑的端到端演化能力
AgentConductor的另一个关键特性是端到端演化能力。当生成代码运行失败时,指挥智能体会接收环境反馈的错误信息,结合记忆中的历史轨迹,对拓扑进行端到端重新生成。这种设计使系统能够持续探索更优的协作形式,而非被困在初始规划中。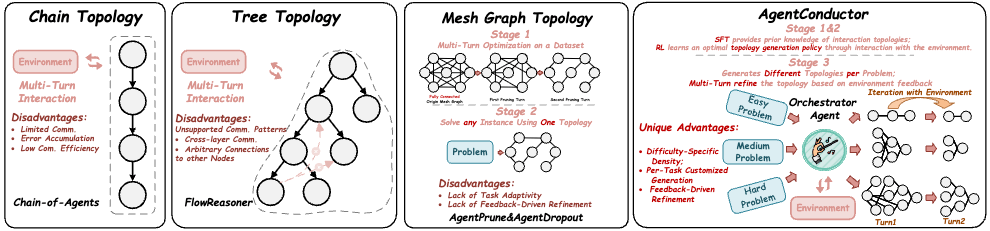
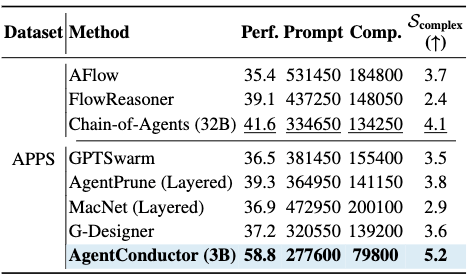
实验数据印证了这一方法的有效性:编码准确率提升14.6%,Token成本降低68%。这组数据说明,真正高效的AI编程团队需要的是面向任务、可随执行反馈动态演化的协作结构,而非僵化的一刀切工作流。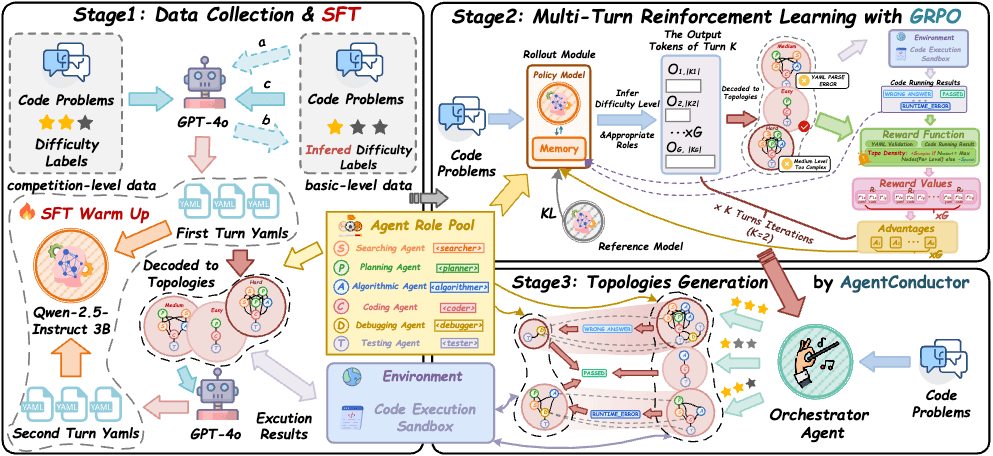
两阶段训练范式解析
该框架采用SFT加GRPO的两阶段训练策略。在监督微调阶段,基于GPT-4o生成的4500个高质量拓扑样本(覆盖三档难度)赋予基础模型拓扑先验。在强化学习阶段,系统将环境反馈的代码报错与多轮拓扑文本共同作为轨迹,通过GRPO算法优化拓扑生成策略以最大化复合奖励。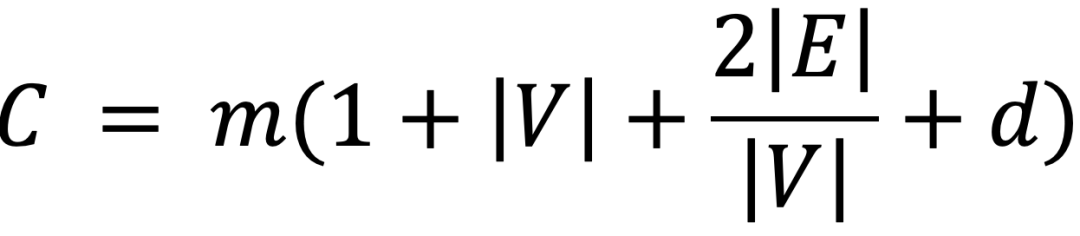
为实现任务自适应,团队提出了拓扑密度评估函数。该函数综合刻画节点数、边密度与图深度对通信成本的影响,实现了从Token成本到拓扑密度的形式化映射。相比之下,传统方法大多简单通过矩阵的秩来衡量交互密度,丢失了多智能体交互的数学含义。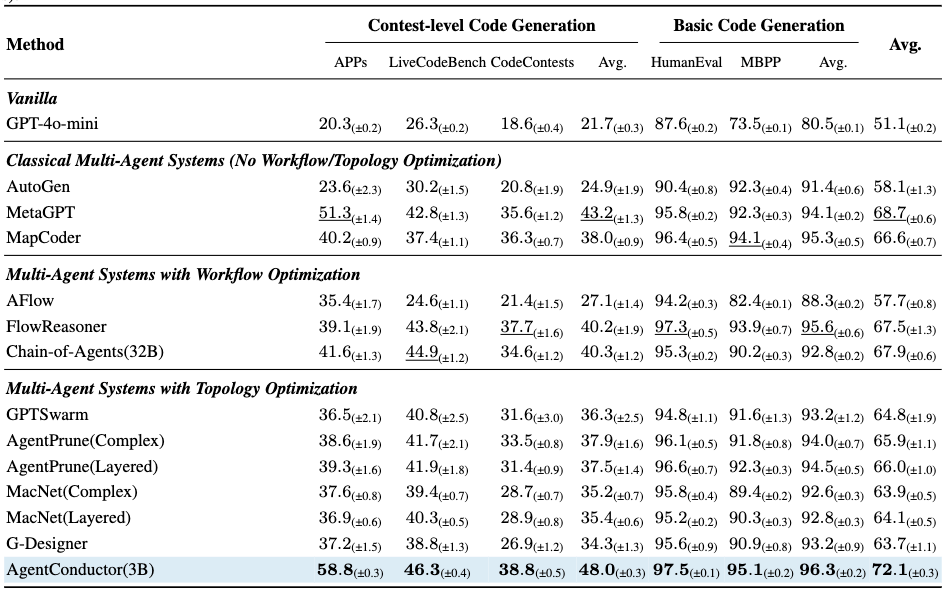
实践启示与应用方向
AgentConductor的核心启示在于:多智能体系统的关键不在于数量,而在于结构的适应性。该框架标志着多智能体研究从静态工作流向动态生态系统的演进,将协作视为可学习、可演化的结构化决策过程。这为复杂编码任务提供了新的解决思路,也为多智能体系统的未来发展指明了方向。